@吴琼等:《基于提示工程的汉语二语文本自动生成研究》
文章采用“提示词 + 零样本学习”“提示词 + 少样本学习”“提示词 + 少样本学习 + 迭代优化”三种方法,考察了大语言模型自动生成符合《国际中文教育中文水平等级标准》一级对话和独白文本的效果。
研究发现,三种方法均可生成一级阅读难度的文本。
“提示词 + 少样本学习 + 迭代优化”法生成符合要求的文本数量最多,但文本较短,所用词汇、语法较为简单;
“提示词 + 少样本学习”法生成的文本长度最长,但存在词汇、语法超等级的情况;
仅使用提示词生成的文本最不受控制,阅读难度最大。
三种生成方法各有优劣,在实际应用中,人工修改和调整仍是必要手段。
1. 引言
随着《国际中文教育中文水平等级标准》的发布,相关教材和教学资源依然相对匮乏,尚未能完全满足国际中文教学的需求。
目前关于GAI的研究主要集中在理论层面,缺乏实际应用案例,亟需开发并推广结合GAI技术的具体实践。
2. 研究背景
2.1 汉语二语文本人工编写的挑战
国际中文教材的编写面临诸多挑战,包括词汇超纲、生词量过大、成语使用越级等问题。这些问题使得现有教材未能有效适配学习者的实际语言水平。
此外,分级读物的数量有限,初级读物特别匮乏,因此对汉语学习者的阅读材料需求急需满足。
2.2 提示工程及提示设计
提示学习(Prompt Learning)是自然语言处理中的一种新兴方法,通过在模型输入中加入特定的“提示”,使得大语言模型能够生成符合特定要求的文本。
提示工程(Prompt Engineering)是这一方法的应用,旨在通过设计、实验和优化输入来引导模型生成高质量、准确的文本。
学术界已提出了多种提示词设计框架,强调提示词应明确、具体、相关且无歧义,以确保生成内容的准确性和质量。
- 如提供任务的背景知识,逐渐增加提示难度
- 在提示末尾重复关键指令,明确要求大语言模型回复高质量的响应
- 在多轮对话中,明确指代关系、精简提示与回复以及重新声明过期上下文
3. 研究设计
3.1 理论基础
- 零样本学习与少样本学习:零样本学习(Zero-shot Learning)无需特定任务的训练,直接生成任务结果;少样本学习(Few-shot Learning)则通过提供少量示范样本,帮助模型更好地理解任务。
- 迭代优化:迭代优化是一种通过持续与大语言模型互动,不断优化文本生成的方法,能有效提升文本的连贯性和准确性。
3.2 工具与材料
本研究使用ChatGPT-4工具,并采用三种提示方法进行汉语文本生成:(对话与独白,均提供《标准》一级词汇表和语法表;学习样本人工编写,对话独白各五篇,每篇不超过 100 字)
- 提示词 + 零样本学习
- 提示词 + 少样本学习
- 提示词 + 少样本学习 + 迭代优化
3.3 提示方法
- 提示词 + 零样本学习:仅输入词汇表和语法表,生成符合初级水平的文本。
- 提示词 + 少样本学习:在词汇表和语法表的基础上,加入少量学习样本,增强文本生成效果。
- 提示词 + 少样本学习 + 迭代优化:通过反复修改生成的文本,优化词汇和语法的使用,以符合标准。(疑惑:可是这样的话,就不能全自动了,得人工一个一个问答)
本研究通过上述三种方法生成对话和独白文本各20个,共计120个文本。(是不是,有点少?)
3.4 数据分析
采用“汉语文本阅读难度分级平台”对文本的易读性得分、总字数、总词数、句子数、平均句长等基础指标及词汇和语法等级分布进行测量。
采用单因素方差分析和克鲁斯卡尔沃利斯检验比较三种方法生成的文本在各项指标得分上的差异。
4. 统计结果分析
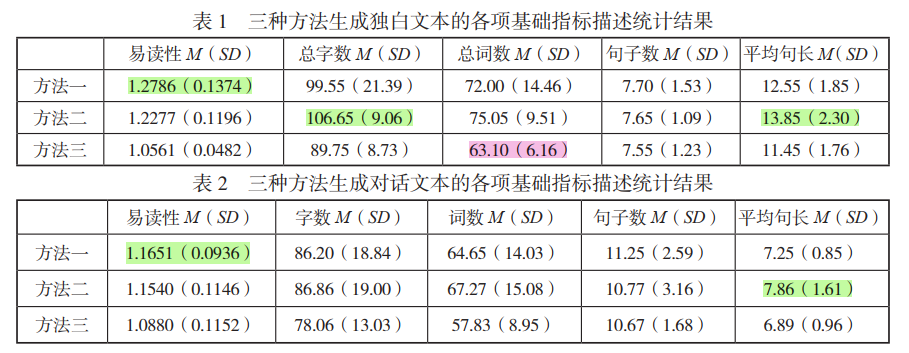
4.1 三种方法生成文本的各项基础指标
4.2 三种方法生成文本的词汇和语法分布
方法三生成文本的词汇、语法超出一级的情况最少
4.3 生成符合要求的文本数量
- 独白文本生成任务:
- 方法一:符合要求的文本1个(5%)
- 方法二:符合要求的文本4个(20%)
- 方法三:符合要求的文本15个(75%)
- 对话文本生成任务:
- 方法一:无符合要求文本
- 方法二:符合要求的文本1个(5%)
- 方法三:符合要求的文本8个(40%)
5. 生成效果讨论
5.1 “提示词 + 零样本学习”生成效果
使用单纯提示词生成的文本易读性较高,但词汇和语法往往超出一级水平,导致生成文本难度较大。
5.2 “提示词 + 少样本学习”生成效果
通过少样本学习,生成的符合要求文本在数量上有所增加,但在文本长度和信息的冗余性方面存在不足。
5.3 “提示词 + 少样本学习 + 迭代优化”生成效果
该方法能够有效控制词汇和语法的难度,生成符合标准要求的文本数量最多。但是,文本的易读性得分较低。
5.4 GAI生成文本的局限性
尽管GAI技术在文本生成中取得一定成功,但其生成的文本仍存在词汇和语法控制不足的问题,且文本长度难以严格控制。
- 第一,大模型的训练数据庞大且多样,而《标准》一级词汇的数量相对有限,这导致了基于《标准》的小规模有限词汇集由于数据量的不足,难以对大模型实现有效的微调
- 第二,大模型在处理特定级别词汇方面的不足也与其训练机制有关。在自然语言处理领域,词汇的选择受到上下文、语义连贯性和语言习惯的影响。虽然可以对模型进行约束,使其在特定任务中优先使用某些词汇,但这种策略往往会与生成文本的自然流畅性和丰富性相冲突
- 第三,深度学习模型在处理语言生成任务时,对频繁和多样的词汇使用有其固有的偏好
6. 结论
本研究表明,基于提示工程的自动文本生成方法能够生成符合《标准》一级要求的汉语文本。尽管如此,GAI仍存在一定局限性,未来需要继续优化提示设计和文本生成过程,以提升其在实际应用中的效果。